Bayesian Demand Modeling & Production MLOps
Forecast the optimal pricing of retail goods with a multi-model ensemble.
Scale retail revenue with Bayesian-optimized price elasticity. Features a multi-model ensemble (DLN, LightGBM, SVR), DVC lineage, and AWS Lambda deployment.
Primary Features
- Multi-model failover system (PyTorch deep learning model, LightGBM, SVR, Elastic Net).
- HPO via Bayesian optimization with Optuna.
- Low-latency caching with ElastiCache Redis.
- Weekly-scheduled ML lineage management with DVC & Prefect.
- Automated data drift and fairness/bias testing (SHAP).
- CI/CD integration with GitHub Actions, AWS CodeBuild, and Snyk for security scanning.
Playground
SKUs
Note: When you trigger a Start Analysis, you may experience a slight delay up to 10 seconds if the system has been idle, due to a cold start of AWS Lambda architecture.This playground implements a warmup trigger to pre-initialize the ML runtime, reducing the latency associated with Lambda cold starts. Yet, loading the PyTorch artifact might take up to 3 seconds when the system cannot find the cache stored in the AWS EC.
Sales volume
Demand curve
Results
Overview
This application aims to help mid-sized retailers find optimal pricing points where the sales is maximized based on the learned demand curve.
Deployed as a microservice on a serverless AWS Lambda & ECR (containerization), the hybrid inference system engineers a multi-layered neural network (PyTorch) and Gradient Boosted Trees (LightGBM) to optimize real-time pricing elasticity, and then secured by a CI/CD pipeline with Snyk and quality gates.
◼ Data Engineering
Time related features are introduced during EDA/ feature engineering process.
Quantity data is logged before training to normalize skewness and reduce the influence of outliers.
◼ Failover with Multi-Model Inference
Employs a hybrid approach combining a multi-layered neural network as the primary model with machine learning models: LightGBM, Support Vector Regressor (SVR), Elastic Net as backups.
This multi-model inference provides a failover mechanism where backup models are loaded when the primary fails in production.
◼ Hyperparameter Optimization
Introduces Bayesian Optimization using the Optuna library for the primary model, with a grid search fallback available.
Introduces the Scikit-Optimize framework for the backup models, with a grid search fallback available.
◼ Production Quality Gates
Data Drift Testing continuously identifies shifts in data distributions in production that could compromise the model's generalization capabilities, using Evently AI.
Fairness Testing validates if the model operates without unwanted bias across different features or segments before serving predictions.
Shipping AI Systems?
I help teams design and deploy scalable ML / RAG / LLM pipelines and MLOps infrastructure.
Or explore:
- Dive deeper 👉 Research Archive
- Learn by building 👉 AI Engineering Masterclass
- Try it live 👉 Playground
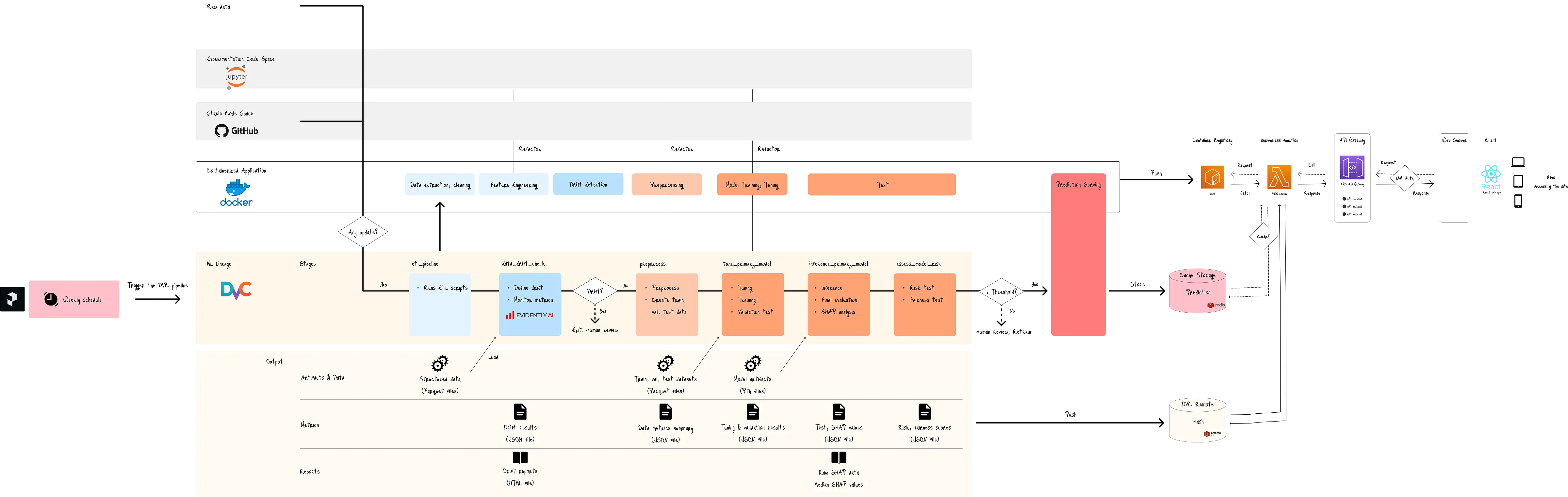
System Architecture
The architecture establishes a scalable, serverless microservice using AWS Lambda, triggered by an API Gateway.
The prediction logic is fully containerized via Docker, which stored in AWS ECR.
Trained models and features are centrally managed in S3, while ElastiCache (Redis) provides a low-latency caching layer for historical data and predictions.
This event-driven setup ensures automatic scaling and pay-per-use efficiency.

Figure A. DVC pipeline and system architecture (Created by Kuriko IWAI)
◼ Core AWS Resources
The infrastructure leverages AWS ecosystem:
Docker / AWS ECR as Microservice container: Packages the prediction logic and dependencies. AWS Lambda pulls the image from ECR for consistent, universal deployment.
AWS API Gateway as REST API endpoint: Routes external client-side UI requests (via a Flask application) to trigger the Lambda function.
AWS Lambda as inference: Executes the inference function, loading the container, models, and features to calculate price recommendations.
AWS S3 as storage & feature store: Stores raw features, trained model artifacts, processors, and DVC metadata for ML Lineage.
AWS ElastiCache and Redis client as caching layer: Stores cached analytical data and past price predictions to improve latency and resource efficiency.
◼ ML Lineage Integration
A dedicated ML Lineage process is integrated using DVC (Data Version Control) and scheduled by Prefect, an open-source workflow scheduler, running weekly.
Lineage Scope (DVC): DVC tracks the entire lifecycle, including Data (ETL/preprocessing), Experiments (hyperparameter tuning/validation), and Models/Prediction (artifacts, metrics).
Data Quality Gate: Models must pass stringent quality checks before being authorized to serve predictions:
Data Drift Tests: Handled by Evently AI to identify shifts in data distribution.
Fairness Tests: Measures SHAP scores and other custom metrics to ensure the model operates without bias.
Automation: Prefect triggers DVC weekly to check for updates in data or scripts and executes the full lineage process if changes are detected, ensuring continuous model freshness and quality.
◼ CI/CD Pipeline Integration
The infrastructure and model lifecycle are managed through a robust MLOps practice using a CI/CD pipeline integrated with GitHub.
Code Lineage: Handled by GitHub, protected by branch rules and enforced pull request reviews.
Source: Code commit to GitHub triggers a GitHub Actions workflow.
Testing & Building: Automated GitHub Actions run:
Test Phase: Runs PyTest (unit/integration tests), SAST (Static Application Security Testing), and SCA (Software Composition Analysis) for dependencies using Synk.
Build Phase: If tests pass, AWS CodeBuild is triggered to build the Docker image and push it to ECR.
Deployment: A human review phase is mandatory between the build and deployment. After approval, another GitHub Actions workflow is manually triggered to deploy the updated Lambda function to staging or production.

Figure B. CI/CD pipeline (Created by Kuriko IWAI)
Shipping AI Systems?
I help teams design and deploy scalable ML / RAG / LLM pipelines and MLOps infrastructure.
Or explore:
- Dive deeper 👉 Research Archive
- Learn by building 👉 AI Engineering Masterclass
- Try it live 👉 Playground
Inference
The process is designed for consistent, automated data and model management through MLOps tools:
The client UI sends a price recommendation request via the Flask application.
The request hits the API Gateway endpoint.
API Gateway triggers the AWS Lambda function.
Lambda loads the Docker container from ECR.
The function retrieves the latest features and model artifacts from S3 and checks ElastiCache/Redis for cached data.
The primary model performs inference on the logarithmically transformed quantity data and returns the optimal price recommendation.
◼ Models Trained
The system utilizes multiple machine learning models to ensure prediction redundancy and reliability. The primary mechanism involves predicting the quantity of product sold at a given price point.
Primary Model: Multi-layered feedforward network (PyTorch).
Role: Serves first-line predictions.
Tuning: Tuned via Optuna's Bayesian Optimization (with grid search fallback).
Backup Models: LightGBM, SVR, and Elastic Net (Scikit-Learn).
Role: Prioritized backups used if the primary model fails, ensuring redundancy.
Tuning: Tuned via the Scikit-Optimize framework.
◼ Performance Evaluation
Models are evaluated using metrics corresponding to both transformed and original data, where a lower value indicates better performance.
For Logged Values: Mean Squared Error (MSE).
For Actual (Original) Values: Root Mean Squared Log Error (RMSLE) and Mean Absolute Error (MAE).
Architected by Kuriko IWAI

Share What You Learned
Kuriko IWAI, "Bayesian Demand Modeling & Production MLOps" in Kernel Labs
https://kuriko-iwai.com/labs/bayesian-demand-modeling-and-mlops
Shipping AI Systems?
I help teams design and deploy scalable ML / RAG / LLM pipelines and MLOps infrastructure.
Or explore:
- Dive deeper 👉 Research Archive
- Learn by building 👉 AI Engineering Masterclass
- Try it live 👉 Playground
Continue Your Learning
If you enjoyed this blog, these related entries will complete the picture:
Building an Automated CI/CD Pipeline for Serverless Machine Learning on AWS
Building a Serverless ML Lineage: AWS Lambda, DVC, and Prefect

Related Books for Further Understanding
These books cover the wide range of theories and practices; from fundamentals to PhD level.

Linear Algebra Done Right

Foundations of Machine Learning, second edition (Adaptive Computation and Machine Learning series)

Designing Data-Intensive Applications: The Big Ideas Behind Reliable, Scalable, and Maintainable Systems

Machine Learning Design Patterns: Solutions to Common Challenges in Data Preparation, Model Building, and MLOps