MLOps & Cloud Infrastructure: Scaling Neural Workloads
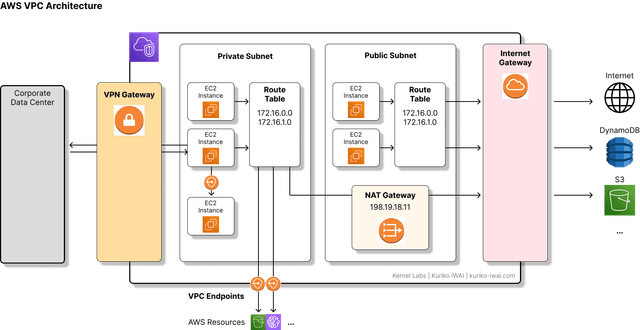
Enterprise engineering for ML lineage with cost-optimized inference. VPC for LLM clusters, Elastic Fabric Adapters, SageMaker orchestration
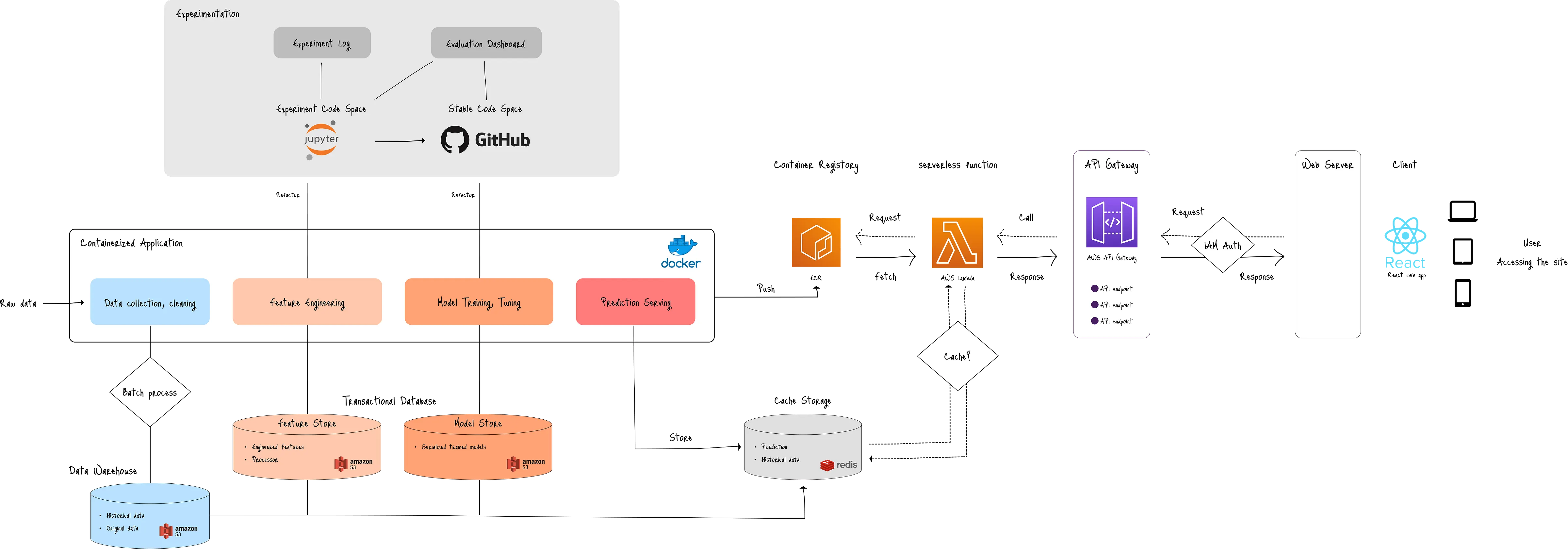
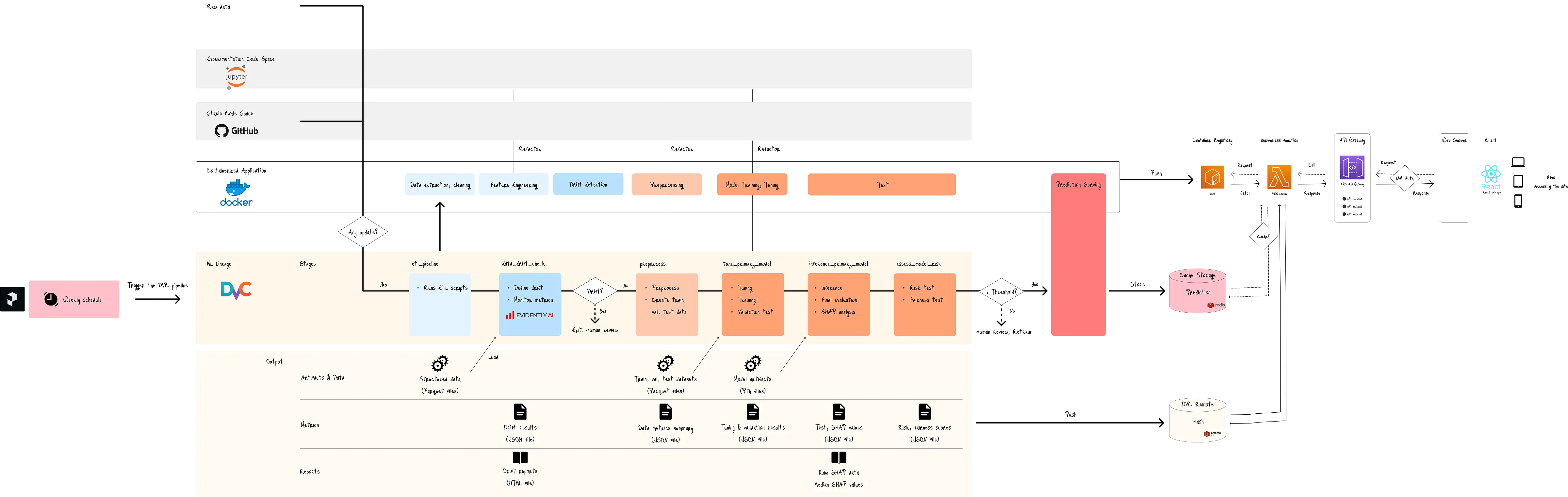
Enterprise-grade engineering of ML lineage from data engineering to model evaluation.
Categories
- Data Pipeline & Feature Engineering:
Architecting robust pipelines for automated data acquisition, missing value imputation, and transformative feature synthesis. - Preprocessing:
Standardizing raw inputs to ensure consistency across training and inference. - Training & Hyperparameter Optimization (HPO):
Systematic tuning of model architectures and loss functions using advanced search strategies and cross-validation. - Evaluation:
Assessing model health through multi - faceted metrics, bias - variance decomposition, and dimensionality reduction via PCA. - Deployment:
CI/CD integration, ML lineage, and ML system architectures.
Data Pipeline & Feature Engineering
This section covers data preparation techniques like data acquistion, augumentation, imputation, feature engieering, and dimensional reduction, architecting robust pipelines for automated data acquisition, missing value imputation, and transformative feature synthesis.
Advanced Cross-Validation for Sequential Data: A Guide to Avoiding Data Leakage
Improve generalization capabilities while keeping data in order
Cross-validation (CV) is a statistical technique to evaluate generalization capabilities of a machine learning model.
Standard K-Fold fails on sequential data.
To avoid data leakage, we need to:
- Maintain temporal orders,
- Use time-series specific validation methods, and
- Prevent autocorrelation between training and validation datasets.
This technical deep dive explores specialized validation strategies—including Walk-Forward, Gap, and hv-Blocked CV—with a performance simulation comparing PyTorch GRU and Scikit-Learn SVR models.