Complete Machine Learning Algorithm & MLOps Research
A full chronological and thematic index of technical deep dives covering LLMs, Transformer architectures, Time-Series, Production MLOps, and more.
How to Build Reliable RAG: A Deep Dive into 7 Failure Points and Evaluation Frameworks
Master how to evaluate the RAG pipeline and solve common failures with DeepEval, RAGAS, TruLens, and Phoenix.
Building a RAG prototype is easy; ensuring it doesn't hallucinate in production is the real engineering challenge.
This article dissects the Seven Failure Points (FPs) of RAG—from missing content to incorrect specificity—and provides a technical roadmap for mitigation using industry-leading evaluation frameworks like DeepEval, RAGAS, and Arize Phoenix.

Building production-grade AI systems?
I help teams design and deploy scalable RAG pipelines, LLM systems, and MLOps infrastructure.
Or explore:
- Dive deeper 👉 Research Archive
- Learn by building 👉 AI Engineering Masterclass
- Try it live 👉 Playground
Understanding Vector Databases and Embedding Pipelines
Explore the mechanics of vector databases, text embedding (Dense, Sparse, Hybrid), and similarity metrics like Cosine Similarity with coding examples.
Traditional databases excel at keywords but fail at context.
To bridge the gap between structured storage and neural processing, engineers utilize Vector Databases and Vectorization.
This technical deep-dive explains how unstructured data is transformed into high-dimensional coordinates, explores the mathematical foundations of similarity scoring, and provides practical Python implementations for dense, sparse, and hybrid embedding tactics.

How to Design a Production-Ready RAG System (Architecture + Tradeoffs) (2026 Edition)
Master industry-standard RAG architectures and how to architect an optimal RAG pipeline, balancing cost, latency, and precision.
Vector search alone is no longer enough for enterprise AI.
While a simple NaiveRAG works for basic FAQs, complex reasoning and multi-document synthesis require specialized pipelines.
This guide dissects the six primary RAG architectures—including GraphRAG and Agentic RAG—and provides a rigorous decision framework to help you choose the right stack for your data’s complexity, reliability requirements, and budget.

Engineer High-Fidelity SLM for Edge AI with Multi-stage Tuning Pipeline
Learn how to engineer high-fidelity Small Language Model (Llama 3.2 3B) with SFT, RKD, and DPO for edge deployment.
Small models trade off intelligence for efficiency.
This technical deep-dive demonstrates how to bridge that gap.
By utilizing a three-phase training pipeline—Supervised Fine-Tuning (SFT), Response Knowledge Distillation (RKD), and Direct Preference Optimization (DPO)—we embed complex human traits into a small model, then deploy it across a high-throughput AWS SageMaker environment and privacy-first edge devices.

Model Distillation Guide: Compressing LLMs for Edge Efficiency
Learn the fundamentals of model distillation with practical implementation tips.
As Large Language Models (LLMs) scale to trillions of parameters, the industry is hitting a wall of latency and cost.
Model Distillation is the essential engineering bridge, allowing developers to compress the intelligence of giants like GPT-4 into lean, edge-ready models.
This guide breaks down the mathematics of loss functions and provides a hands-on roadmap for deploying high-performance student models.

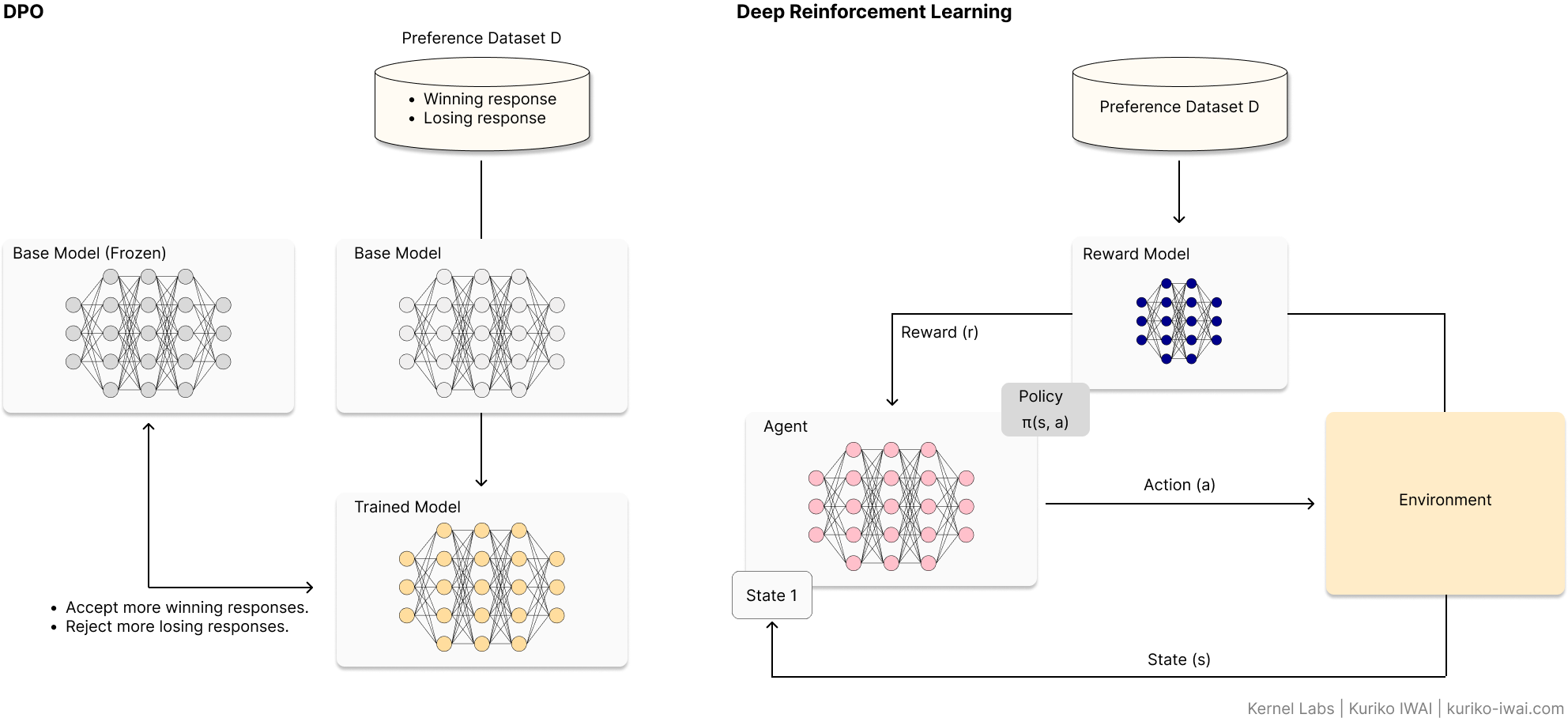
Aligning LLMs with Direct Preference Optimization (DPO)
Learn the fundamentals and follow a technical walkthrough with Unsloth and Llama.
Reinforcement Learning from Human Feedback (RLHF) has long been the gold standard for LLM alignment, but its complexity—requiring separate reward models and unstable PPO loops—is a significant barrier.
Direct Preference Optimization (DPO) simplifies this by treating alignment as a direct classification problem.
This article breaks down the mathematical foundation of DPO, provides a hands-on implementation guide using the Unsloth framework, and explores the strategic trade-offs between DPO and traditional RLHF.
A Technical Guide to QLoRA and Memory-Efficient Fine-Tuning
Master how QLoRA enables 70B model tuning on consumer GPUs, leveraging NF4, Double Quantization, and Paged Optimizers.
As Large Language Models scale, the hardware requirements for fine-tuning have become prohibitive for the average developer.
Quantized Low-Rank Adaptation (QLoRA) changes the game by shrinking VRAM requirements by over 95%.
This deep dive explores the core mechanics—NormalFloat 4 (NF4), Double Quantization, and Paged Optimizers—that allow a 70B parameter model to be tuned on a single 48GB GPU without sacrificing 16-bit performance levels.

Is 4-Bit All You Need? The Math Behind Modern LLM Compression
The Engineer’s Guide to LLM Quantization. Learn How Quantization Makes 70B Models Run on Local GPU.
An technical exploration of numerical precision in Large Language Models.
This article deconstructs standard FP32 formats and evaluates modern quantization schemes—including Integer, NormalFloat, and Microscaling—to help developers balance computational efficiency with model fidelity.

Scaling Securely - A Technical Deep Dive into AWS VPC Architecture for MLOps
Master AWS VPC for Machine Learning and MLOps with Practical Use Cases.
As Large Language Models (LLMs) transition from research to production, the security frontier has shifted to the network layer.
This technical guide explores how to architect an AWS Virtual Private Cloud (VPC) specifically for ML workloads.
I move beyond theory to provide step-by-step CLI configurations for four critical use cases: from cost-efficient tabular pipelines to high-performance distributed LLM training using Elastic Fabric Adapters (EFA).
Learn how to eliminate data egress fees and harden your infrastructure against unauthorized access.

Building LoRA Multi-Adapter Inference on AWS SageMaker
Decoupling Weights for Scale: A Guide to Dynamic Multi-Adapter Orchestration.
This technical guide explores the implementation of high-density LoRA (Low-Rank Adaptation) multi-adapter inference.
I demonstrate how to move away from costly dedicated model endpoints toward a unified architecture using Amazon SageMaker Multi-Model Endpoints (MME).
By decoupling the heavy base model weights from lightweight task-specific adapters, developers can achieve a 96% reduction in overhead while maintaining low-latency switching across divergent domains like medical documentation, sales schema enforcement, and linguistic localization.

Deconstructing LoRA: The Math and Mechanics of Low-Rank Adaptation
Master the math of rank decomposition, hyperparameter tuning, and tips to avoid common pitfalls
While big tech uses massive clusters for LLM tuning, the real world requires VRAM efficiency.
This deep dive explores Low-Rank Adaptation (LoRA), explaining how it achieves full-tuned performance with 1/10,000th of the expense.
Using Qwen-3-1.7B as a reference, we break down the linear algebra of rank decomposition, provide a guide for tuning hyperparameters (r and alpha), and address critical security pitfalls like data-centric and extraction attacks.

Building production-grade AI systems?
I help teams design and deploy scalable RAG pipelines, LLM systems, and MLOps infrastructure.
Or explore:
- Dive deeper 👉 Research Archive
- Learn by building 👉 AI Engineering Masterclass
- Try it live 👉 Playground
The Definitive Guide to LLM Fine-Tuning: Objectivee, Mechanisms, and Hardware
Master LLM fine-tuning with the framework for base model selection, tuning mechanisms, and hardware constraints
A comprehensive technical deep-dive into the methodologies of fine-tuning Large Language Models (LLMs).
This guide breaks down the transition from foundation models to task-specific experts, covering learning objectives like SFT and DPO, and efficient architectural mechanisms including LoRA, QLoRA, and ReFT.
Ideal for developers looking to optimize model performance while balancing GPU constraints and data requirements.

Mastering the Bias-Variance Trade-Off: An Empirical Study of VC Dimension and Generalization Bounds
How model complexity and data size impact generalization performance in machine learning
While the bias-variance trade-off is a familiar hurdle in supervised learning, the Vapnik-Chervonenkis(VC) dimension offers the mathematical rigor needed to quantify a model's capacity.
This article evaluates the relationship between the VC dimension, VC bounds, and generalization error through empirical testing on synthetic datasets, demonstrating how theoretical limits translate to real-world model performance.

The Reasoning Wall: A Comparative Benchmark of Llama 3.2 vs. Qwen 3
Stress-testing multi-hop logic chains using Multi-LogiEval, Process Benchmarking, and Thought-to-Output Ratios
Most LLM benchmarks fail to identify exactly where logical coherence collapses.
This report establishes a framework for measuring Reasoning Depth (d) across three task tiers. By evaluating Llama 3.2 and Qwen 3 through four granular metrics—including Robustness Coefficients and Thought-to-Output ratios—we identify the reasoning wall and provide architectural recommendations for production-scale deployment.